It’s Alive! A Mary Shelley Interpretation of Current AI Culture
Friday: January 26th, 2024
Introduction
As many of you already know, the story of Mary Shelley’s Frankenstein is a novel revolving around the exploits of an eccentric scientist by the name of Victor Frankenstein. It’s considered one of the earliest works of science fiction and has had a significant impact on literature and popular culture. Surprisingly, despite the novel being published in 1818, it is amazingly allegorical to modern day life especially in the today’s information age. The novel’s themes which include the consequences of playing god, the dangers of unchecked scientific ambition, and the nature of humanity have never been more prevalent than ever especially in regards to AI.
For those of you who don’t know, the areas of machine learning (especially in the facet of neural networks) is a relatively new field in the eyes of the computer science industry. Several important scientific figures have come up with their techniques only within the past 40 years or so; with the seeds being laid in the field by Frank Rosenblatt sometime in the 50s through the creation of the perceptron. The neural network field floundered in the 60s and 70s seeing a resurgence sometime around the 1980s. This resurgence was none more important than for the contributions of a computer scientist by the name of Geoffrey Hinton who along with the help of David Rumelhart and Ronald Williams made important contributions to the development of backpropagation.
The Parallels
I find it very amusing and at the same time scary the parallels between the revolutions of neural networks and the themes taught in Mary Shelley’s book. In the book, Victor Frankenstein becomes obsessed with the idea of creating life. Eventually he succeeds in bringing a creature to life through his scientific experiments, but is horrified by his creation whereby he abandons it. The creature feeling abandoned by it’s creator becomes bitter and eventually seeks revenge. The monster even kills Victor’s wife. In the end, Dr. Frankenstein dies having wished he never made it at all. This is directly emblematic to humanities plight to harness human intelligence in the form of machines with Geoffry Hinton allegorically shadowing Dr. Frankenstein.
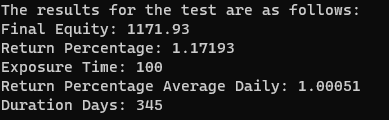
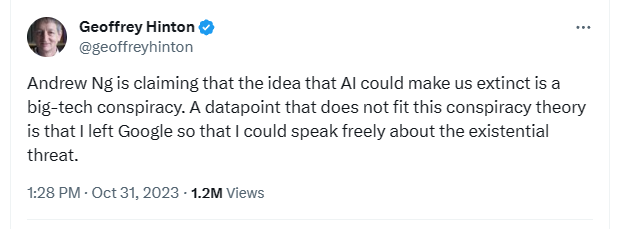
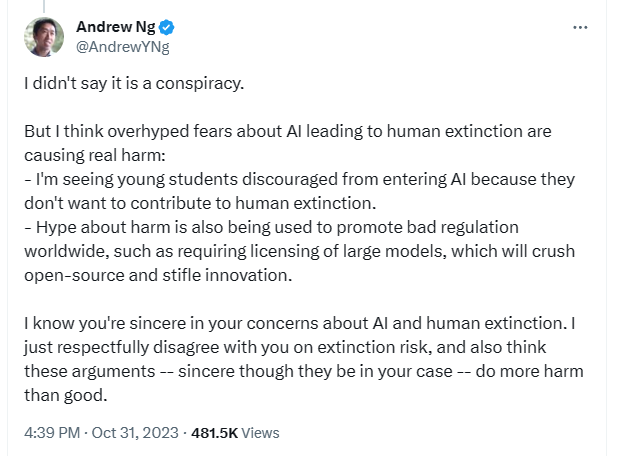
Geoffry Hinton has been very outspoken recently about his absolute reversion to the use of his research. He has even outright called out the existential threat of modern AI and the manipulative uses of big corporations to replace the need for human labour. I think it goes without saying but if AI were to fundamentally mimic human thought and behaviour it would be the end of the modern capitalistic system as we know it; with the need for the transfer of wealth to be nonexistent. This is primarily due to the fact that the economy needs money to change hands to satisfy demand to produce and purchase goods that we all need. There is even a plethora of tweets made by the man to validate my claims which can be found here and are included as images below.
The Consequences
Thinking about this, I can’t help but think about the speech presented by Neil Postman called “Five Things We Need to Know About Technological Change” which was delivered in 1998 by the man himself to a group of religious leaders and theologians in Denver, Colorado. In the second idea he talks about how despite what is preached the advantages and disadvantages of a new technology are never distributed evenly amongst the population. In the speech he says:
"This leads to the second idea, which is that the advantages and disadvantages of new technologies are never distributed evenly among the population. This means that every new technology benefits some and harms others. There are even some who are not affected at all. … The questions, then, that are never far from the mind of a person who is knowledgeable about technological change are these: Who specifically benefits from the development of a new technology? Which groups, what type of person, what kind of industry will be favored? And, of course, which groups of people will thereby be harmed?"
"These questions should certainly be on our minds when we think about computer technology. There is no doubt that the computer has been and will continue to be advantageous to large-scale organizations like the military or airline companies or banks or tax collecting institutions. And it is equally clear that the computer is now indispensable to high-level researchers in physics and other natural sciences. But to what extent has computer technology been an advantage to the masses of people? To steel workers, vegetable store owners, automobile mechanics, musicians, bakers, bricklayers, dentists, yes, theologians, and most of the rest into whose lives the computer now intrudes? These people have had their private matters made more accessible to powerful institutions. They are more easily tracked and controlled; they are subjected to more examinations, and are increasingly mystified by the decisions made about them. They are more than ever reduced to mere numerical objects. They are being buried by junk mail. They are easy targets for advertising agencies and political institutions."
"In a word, these people are losers in the great computer revolution. The winners, which include among others computer companies, multi-national corporations and the nation state, will, of course, encourage the losers to be enthusiastic about computer technology. That is the way of winners, and so in the beginning they told the losers that with personal computers the average person can balance a checkbook more neatly, keep better track of recipes, and make more logical shopping lists. Then they told them that computers will make it possible to vote at home, shop at home, get all the entertainment they wish at home, and thus make community life unnecessary. And now, of course, the winners speak constantly of the Age of Information, always implying that the more information we have, the better we will be in solving significant problems--not only personal ones but large-scale social problems, as well. But how true is this? If there are children starving in the world--and there are--it is not because of insufficient information. We have known for a long time how to produce enough food to feed every child on the planet. How is it that we let so many of them starve? If there is violence on our streets, it is not because we have insufficient information. If women are abused, if divorce and pornography and mental illness are increasing, none of it has anything to do with insufficient information. I dare say it is because something else is missing, and I don't think I have to tell this audience what it is. Who knows? This age of information may turn out to be a curse if we are blinded by it so that we cannot see truly where our problems lie. That is why it is always necessary for us to ask of those who speak enthusiastically of computer technology, why do you do this? What interests do you represent? To whom are you hoping to give power? From whom will you be withholding power?"
You can find the whole speech here for those who are interested in reading it.
All that being said, the advent and somewhat surreptitious growth of AI is something that we should be extremely cautious about. I find it incredibly disturbing that quite literally everyone I know in the computer industry works in some form or another with AI. This is especially disturbing given the fact that the creators themselves (like Geoffry Hinton) are warning of their existential threat to human engagement and existence. It’s similar in lore to the assembly line worker creating the robotic arm that would eventually render himself/herself obsolete.
To echo what Neil stated in his speech, we have to be aware of who specifically benefits from the new technology? Who will be favoured? And lastly who will be harmed? We should be aware of the biases and conflicts of interest of those who promote it. One current researcher and advocator of the field who comes to mind is Andrew Ng. It is very humorous that he even in fact commented on one of Geoffry’s tweets about the threat of his research saying stuff along the line that it discourages students from pursuing the field. Could he have made that comment due to the fact that he otherwise owns Coursera which charges people to learn about those very topics. Probably!
Conclusion
To conclude, these parallels to Mary Shelley’s novel make me very uneasy. No one can predict the future, especially in the ecosystem of human life, with the advent of a new technology of this magnitude. We have to be aware of the themes of the book in regards to these inventions; especially the consequences of playing god, and the dangers of unchecked scientific ambition. Whether regulation in the area could avoid future harms is yet to be known although I doubt it due to its uncertainty. In the novel, when Victor tries to take on the role of a divine power by creating life he never would have foreseen the consequences. These being ethical dilemmas, loss of humanity, political ramifications and psychological impact. Now in the modern age, in the advent of trying to harness human thought in the form of a computer most likely will have the same consequences. The final result is yet to be known.
- Nicholas Ierfino